Fine-Tuning a Small LLM from Scratch with LoRA
Small language models are getting remarkably capable. Alibaba’s Qwen3.5 small model series, ranging from 0.6B to 7B parameters, runs on a laptop and punches well above its weight on benchmarks. I have been building a personal GTD system powered by these small, local models. The models understood my tasks, but they weren’t reliable: they’d return prose instead of the structured JSON the pipeline expected, or hallucinate values outside the expected schema. I didn’t need a smarter model, I needed a more obedient one.
Fine-tuning was the obvious fix, and I took it as an excuse to go deep: no frameworks, no abstractions, just PyTorch, LoRA, and a laptop.
What is Supervised Fine-Tuning?
SFT is conceptually simple: you have input-output pairs, and you train the model to maximize the probability of the output given the input. It’s the same language modeling objective used in pretraining, just on your curated dataset.
Given a dataset of
where
This is just cross-entropy loss over the vocabulary at each position, teacher-forced. Nothing fancy, the same loss used to pretrain the model in the first place, but now on your specific task data.
The Problem with Full Fine-Tuning
A model like LLaMA-7B has ~7 billion parameters. Fine-tuning all of them requires:
- Storing the full model in memory (~28GB in fp32)
- Storing optimizer states (another ~56GB for Adam)
- Gradient computation across all layers
For most tasks, this is overkill. The pretrained weights already encode useful representations. You just need to nudge them slightly.
LoRA: Low-Rank Adaptation
LoRA, introduced by Hu et al. (2021), is based on a key observation: the weight updates during fine-tuning have low intrinsic rank. Instead of updating a full weight matrix
where
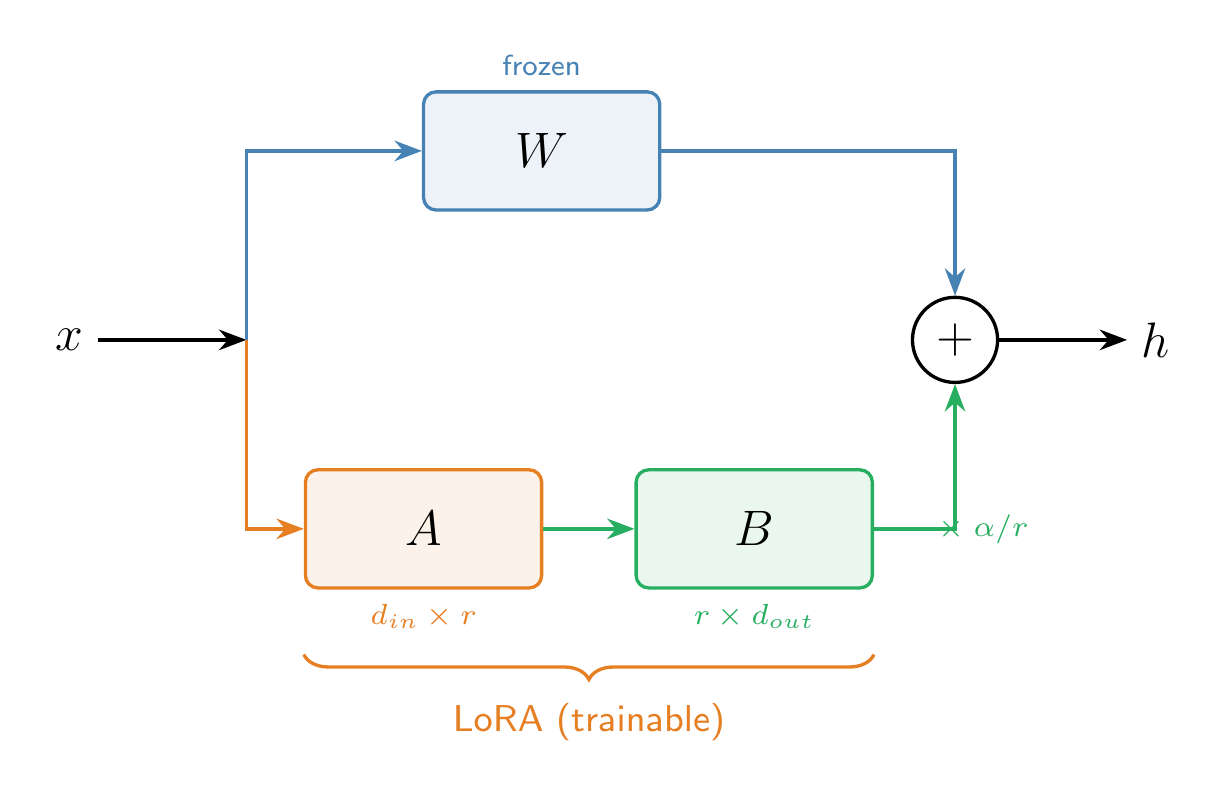
During training:
is frozen (no gradients) - Only
and are trained - The forward pass computes
The number of trainable parameters drops from
Scaling Factor
LoRA introduces a scaling factor
where
Which Layers to Adapt?
The original paper found that adapting the query and value projection matrices (
Step-by-Step Implementation
Let’s build this from scratch in pure PyTorch. No HuggingFace Trainer, no PEFT library. We’ll fine-tune TinyLlama (1.1B parameters) to respond with structured JSON using a synthetic dataset.
1. Generate Training Data
We need instruction/output pairs where the output is always structured JSON:
1 | import json |
Each example looks like:
1 | { |
The base model would respond with free-form text. After SFT, it should produce JSON.
2. Format and Tokenize
We concatenate instruction and output into a single sequence with a template:
1 | def format_and_tokenize(examples, tokenizer, max_length=512): |
The model learns to predict every token in this sequence, but the signal that matters is the response portion. The instruction tokens provide context.
3. Implement LoRA from Scratch
This is the core of it. A LoRA layer wraps a frozen linear layer with two small trainable matrices:
1 | import torch |
That’s it. A is initialized with small random values, B starts at zero so the LoRA path initially contributes nothing. The original weights are frozen.
4. Apply LoRA to the Model
We replace the q_proj and v_proj layers in every attention block:
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
Only 0.1% of parameters are trainable. The adapter weights will be ~4MB.
5. Training Loop
A standard PyTorch training loop. Nothing hidden behind abstractions:
1 | from torch.utils.data import DataLoader, TensorDataset |
On an M-series Mac (MPS), you should see the train loss drop sharply in the first epoch, with validation loss tracking closely.
6. Evaluate
Generate from both the base model and our LoRA-injected model:
1 | def generate(model, tokenizer, prompt, max_new_tokens=128): |
Results
Here are the actual results from training TinyLlama 1.1B on 500 synthetic examples (400 train / 100 validation) for 3 epochs.
Training Loss
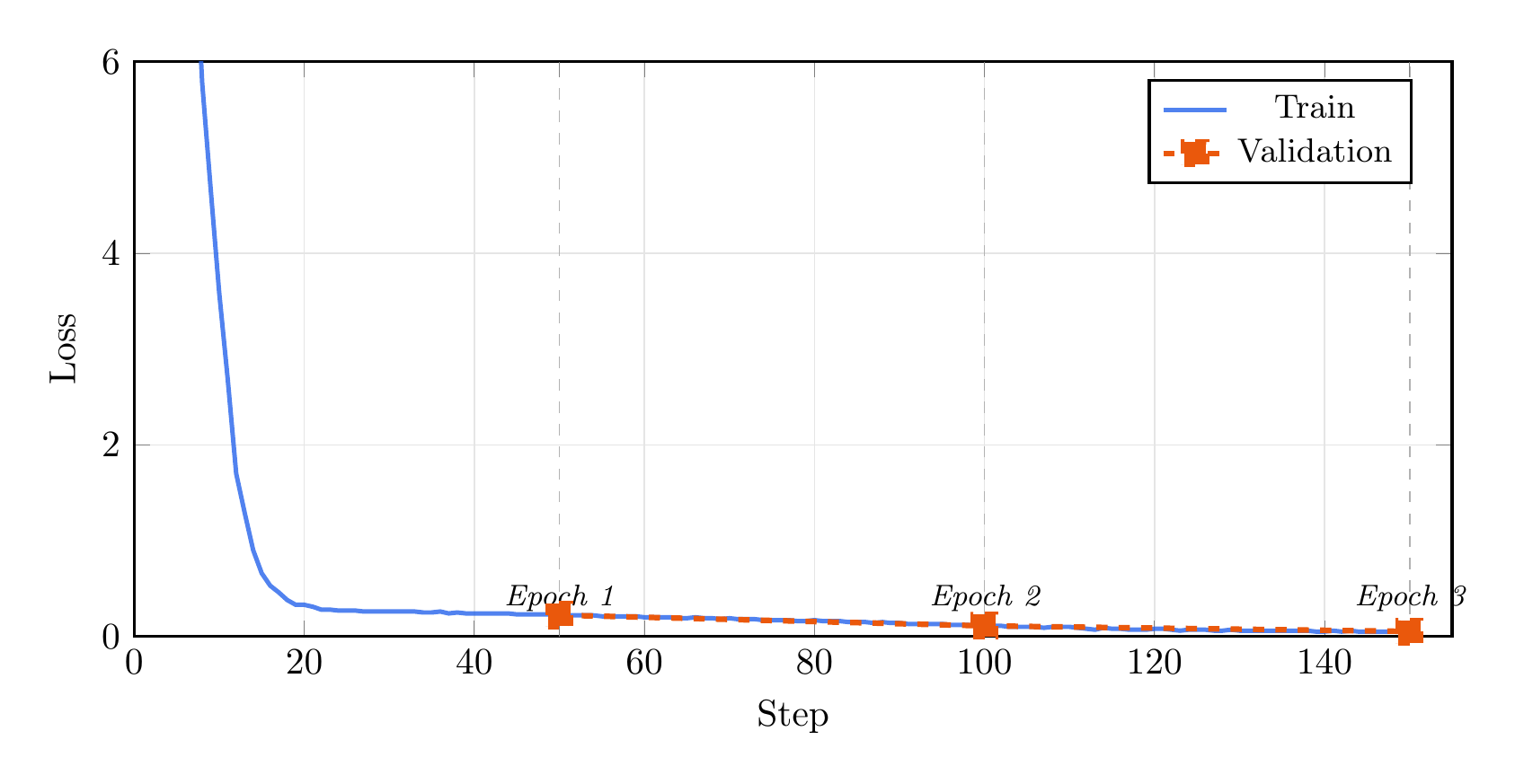
Training completed on Apple MPS (M-series Mac). The train loss drops sharply in the first epoch as the model learns the JSON structure, then steadily decreases through epochs 2 and 3. Validation loss tracks closely throughout, ending at 0.05 with no sign of overfitting.
Base Model vs. Finetuned

The base model interprets “structured format” literally and produces Go code. After SFT, the same prompt on an unseen topic yields clean, parseable JSON.
A note on correctness: Look closely at the fine-tuned output. The format is right, but the content isn’t. Go is listed with features like “dynamic typing” and “interpreted,” which are wrong. The model learned how to respond (valid JSON) but is confabulating facts for topics outside the training set. With only 500 synthetic examples covering a handful of technologies, this is expected: the model has no signal for what Go’s features actually are, so it fills in plausible-sounding values. This highlights a broader risk with SFT: fine-tuning too aggressively can also degrade the model’s existing knowledge (sometimes called catastrophic forgetting). In practice, you always want a regression suite, a broad evaluation that checks the model’s general capabilities haven’t degraded after fine-tuning.
Key Takeaways
- SFT is just next-token prediction on curated data, the same objective as pretraining
- LoRA makes this practical by training ~0.1% of parameters via low-rank matrix decomposition
- A few hundred examples and 3 epochs is enough to teach a clear pattern
- The adapter weights are tiny (~4MB) and can be swapped without reloading the base model
References
- Hu, E. J., et al. “LoRA: Low-Rank Adaptation of Large Language Models.” ICLR 2022. arXiv:2106.09685
- Dettmers, T., et al. “QLoRA: Efficient Finetuning of Quantized Language Models.” NeurIPS 2023. arXiv:2305.14314
- The full code for this post is available at github.com/mrrostam/blog-code/sft-lora
Appendix: Frameworks and Tools
Everything in this post was implemented in pure PyTorch to make the mechanics visible. If you’re moving beyond experimentation, these frameworks handle the boilerplate and scale better:
- TRL (Transformer Reinforcement Learning): Hugging Face’s library for SFT, DPO, PPO, and RLHF.
SFTTrainerhandles formatting, packing, and LoRA integration in a few lines. The most popular choice for fine-tuning workflows. - Axolotl: YAML-config-driven fine-tuning. Supports LoRA, QLoRA, full fine-tuning, multi-GPU, Flash Attention, and many dataset formats out of the box. Good for running experiments without writing training code.
- Unsloth: Optimized for speed. 2x faster training and 70% less memory through custom Triton kernels. Drop-in replacement for Hugging Face trainers, supports Llama, Qwen, Mistral, Gemma, and more.
- LLaMA-Factory: Web UI and CLI for fine-tuning 100+ LLMs. Supports SFT, RLHF, DPO, and various quantization methods. Lowest barrier to entry.
- PEFT (Parameter-Efficient Fine-Tuning): Hugging Face’s library for LoRA, QLoRA, prefix tuning, prompt tuning, and other adapter methods. Works with any Hugging Face model.
- torchtune: PyTorch-native fine-tuning library from the PyTorch team. Clean, modular, and well-documented. Good if you prefer staying close to raw PyTorch without the Hugging Face ecosystem.