Teaching a Small LLM to Prefer JSON Over Prose
In my previous post, I used SFT with LoRA to teach a small model to respond in structured JSON. It worked, but SFT is imitation learning: you show the model exactly what to produce, and it copies the pattern. What if instead of demonstrating the right answer, you just tell the model which answer you prefer?
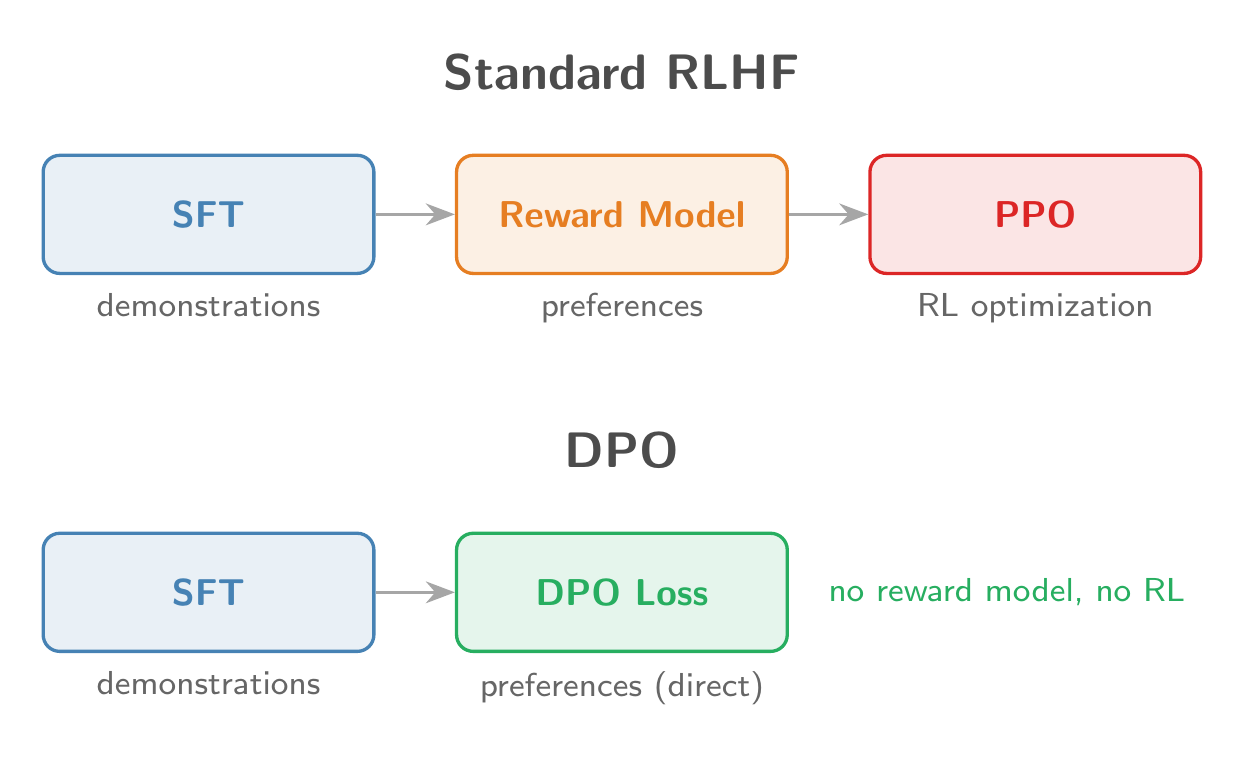
That is the idea behind RLHF, and it is how most production LLMs are aligned after pretraining. The traditional approach uses PPO with a separate reward model, which is notoriously finicky. DPO (Direct Preference Optimization) sidesteps all of that, collapsing the reward model and RL loop into a single supervised loss function.
The RLHF Pipeline (and Why It Is Hard)
The standard RLHF pipeline has three stages:
- SFT: fine-tune on demonstrations
- Reward Model: train a model to score responses using human preference data
- PPO: optimize the policy against the reward model using reinforcement learning
Stage 3 is the painful part. PPO requires generating responses (expensive), scoring them, computing advantages, and carefully managing a KL penalty to prevent reward hacking. DPO collapses stages 2 and 3 into a single supervised learning step.
The Bradley-Terry Preference Model
Both the reward model and DPO start from the same assumption. The Bradley-Terry model (1952) says: given two responses
where
In standard RLHF, you train a reward model on this, then optimize the policy against it with a KL constraint:
The DPO Derivation
The key insight from Rafailov et al. (2023): the KL-constrained problem above has a closed-form optimal policy:
Rearranging for the reward and substituting back into Bradley-Terry (the
In plain English: make the model assign relatively higher probability to the preferred response (compared to the reference model), and relatively lower probability to the rejected one.
DPO vs PPO
| PPO | DPO | |
|---|---|---|
| Models needed | 3 (policy + reward + reference) | 2 (policy + reference) |
| Training | Online RL (generate, score, update) | Offline supervised (static dataset) |
| Stability | Tricky (reward hacking, KL tuning) | Stable (just cross-entropy) |
| Compute | Heavy (generation at each step) | Light (forward passes only) |
Step-by-Step Implementation
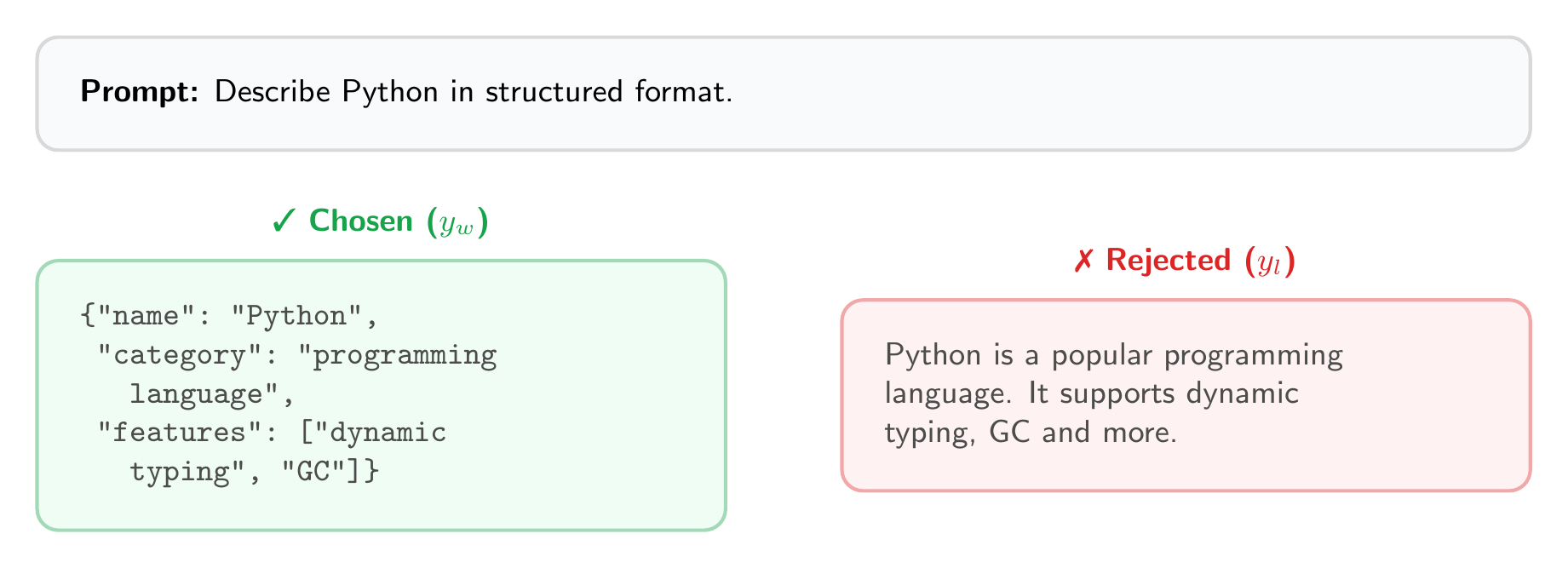
1. Generate Preference Data
Each example needs a prompt, a preferred (chosen) response, and a dispreferred (rejected) response:
1 | import json |
The preference signal is clear: structured JSON is preferred over free-form text.
2. Compute Log Probabilities
The core building block. Given a model and a sequence, compute the sum of log-probabilities for the response tokens only:
1 | import torch |
3. The DPO Loss
Remarkably short:
1 | def dpo_loss(policy, ref_model, batch, beta=0.1): |
That is the entire DPO algorithm. The loss pushes the policy to widen the gap between chosen and rejected log-probs, relative to what the reference model would do.
4. Training Loop
We reuse the LoRALinear and inject_lora from the SFT post:
1 | from transformers import AutoModelForCausalLM |
Note the lower learning rate compared to SFT (
Results
Training TinyLlama 1.1B with DPO on 500 preference pairs (400 train / 100 val) for 3 epochs on Apple MPS:
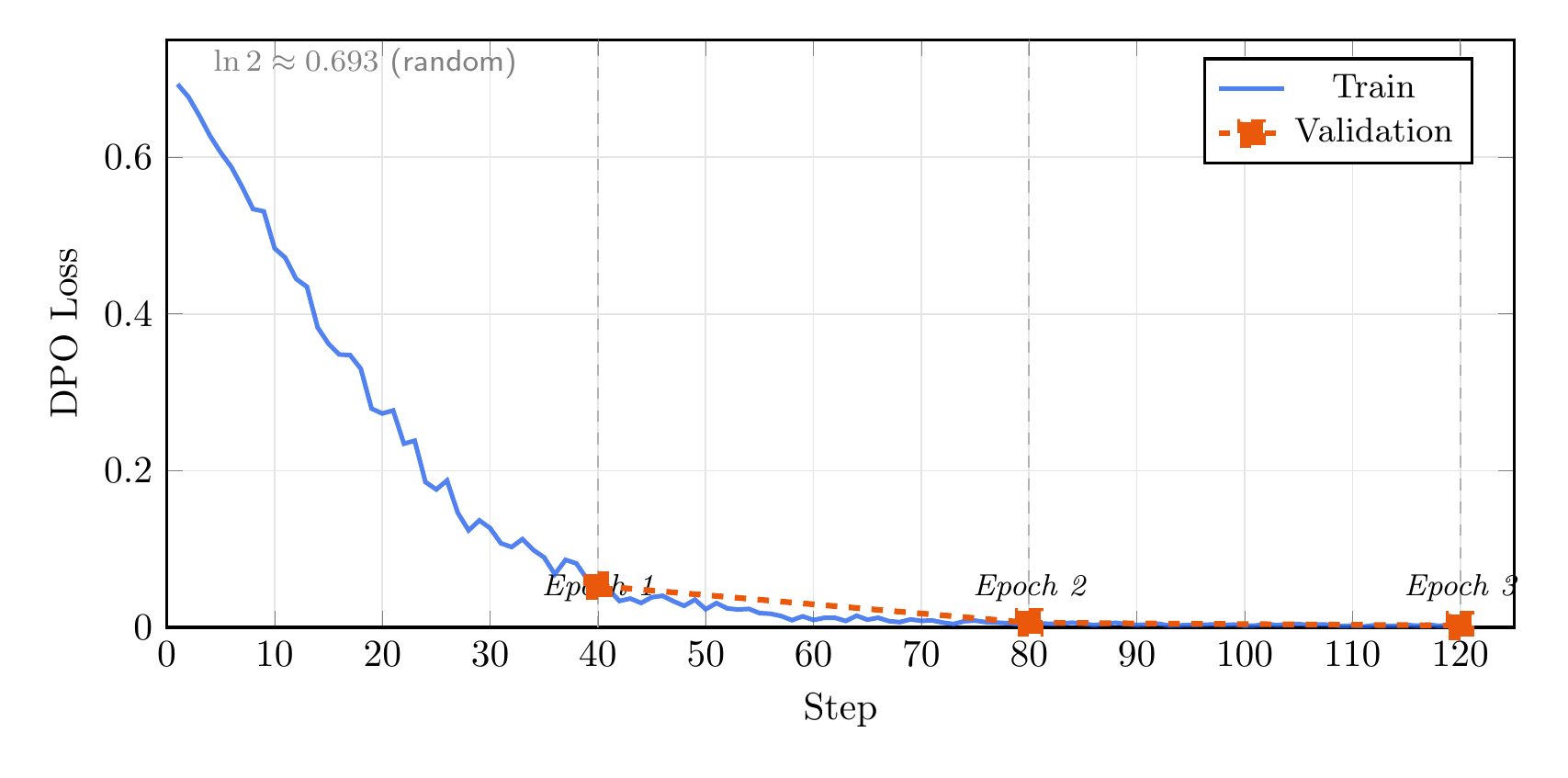
The loss starts at
By step 30 (75% through epoch 1), the model has already learned to strongly prefer JSON over free-text. Validation loss tracks closely throughout, ending at 0.003 with no sign of overfitting.
Before and After

The base model interprets “structured format” as a cue for an explanatory paragraph. After DPO, the same prompt on an unseen topic yields parseable JSON.
How DPO Outputs Differ from SFT
An interesting difference emerges when you compare DPO and SFT outputs on the same prompt. The SFT model (from the previous post) produces outputs that closely match the training schema: exact field names, values drawn from the training distribution. The DPO model produces valid JSON but is more creative. It adds fields like "description" that were not in the training data, and generates feature descriptions in its own words rather than copying from the training set.
This makes sense. SFT directly maximizes the likelihood of the training outputs (imitation), while DPO only learns that JSON is preferred over free-text (preference). The DPO model has more freedom in how it satisfies that preference.
The Implicit Reward
An elegant property of DPO: even though we never trained a reward model, the policy implicitly defines one:
The reward of a response is how much more likely the trained policy thinks it is compared to the reference. In the reward modeling post, I build an explicit reward model and compare its scores to this implicit reward.
When to Use DPO vs SFT
- SFT when you have clear input/output demonstrations and want to teach a new capability
- DPO when you have preference pairs and want to steer the model toward a preferred style
- SFT then DPO is the standard pipeline: SFT teaches the behavior, DPO refines it
References
- Rafailov, R., et al. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” NeurIPS 2023. arXiv:2305.18290
- Ouyang, L., et al. “Training language models to follow instructions with human feedback.” NeurIPS 2022. arXiv:2203.02155
- Bradley, R. A. & Terry, M. E. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.” Biometrika, 1952.
- The full code for this post is available at github.com/mrrostam/blog-code/dpo