Reward Modeling: Scoring LLM Outputs
In the DPO post, I used DPO to skip the reward model entirely. DPO’s whole selling point is that you don’t need one. But building a reward model completes the picture of how RLHF actually works, and it lets us do something interesting: compare the explicit reward model’s scores to DPO’s implicit reward and see if they agree.
What Is a Reward Model?
A reward model takes a (prompt, response) pair and outputs a scalar score representing how “good” the response is. In the RLHF pipeline, this score is what PPO optimizes against.
Architecturally, you take a pretrained language model, strip the LM head, and replace it with a single linear layer that projects the last hidden state to a scalar:
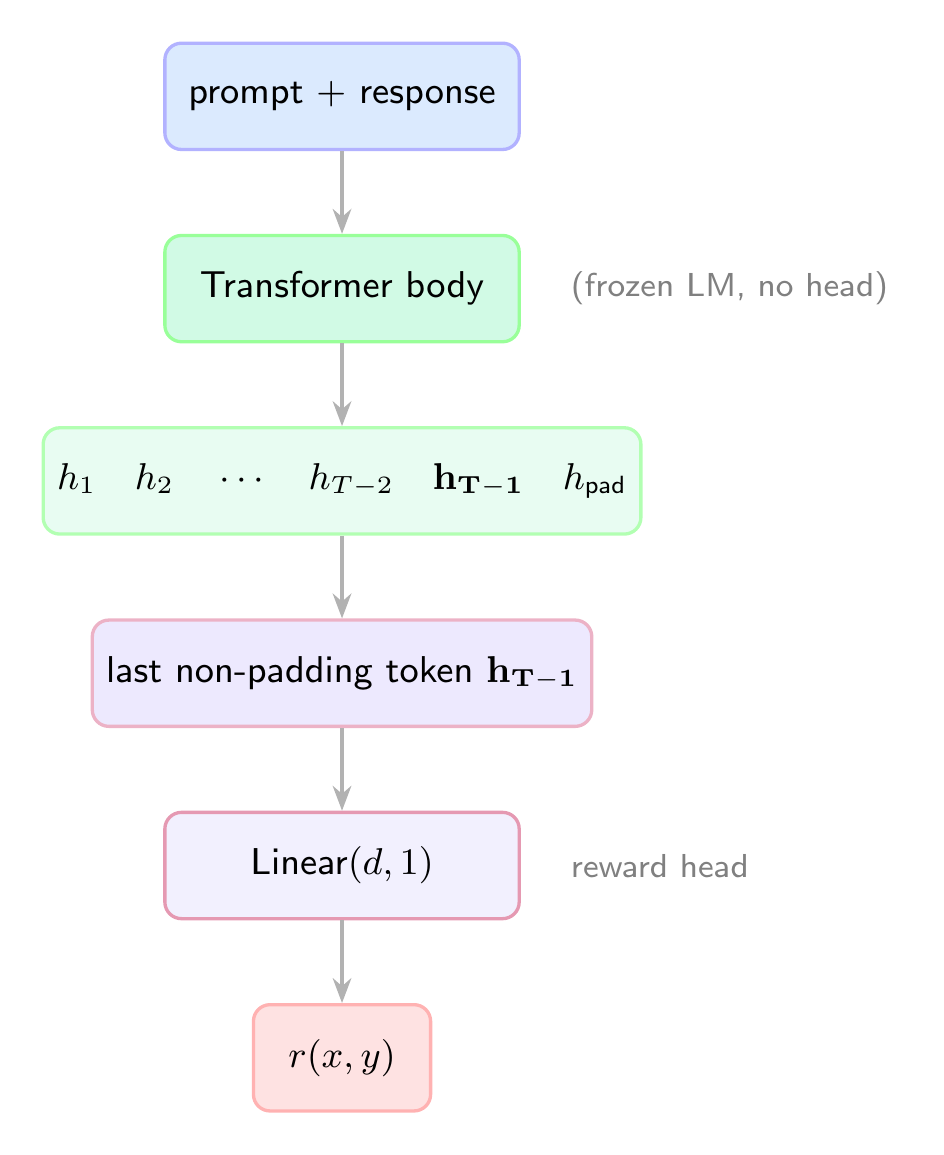
The key detail: we extract the hidden state at the last non-padding token, not the last position. That single number is the reward.
The Bradley-Terry Loss
Given a preferred response
This pushes the model to assign a higher score to the preferred response. It is the same loss used in Elo rating systems: the probability that “player A beats player B” depends on the difference in their ratings. And it is the same Bradley-Terry model that DPO builds on.
Implementation
The Reward Head
1 | import torch |
base_model.model gives us the transformer body without the language modeling head. We add our own reward_head that maps from hidden dimension (2048 for TinyLlama) to a single scalar.
Training
The training loop processes preference pairs and applies the Bradley-Terry loss:
1 | import torch.nn.functional as F |
Beyond the loss, we track pairwise accuracy: what fraction of the time does the reward model correctly rank the chosen response above the rejected one?
Results
Training on the same 500 preference pairs from the DPO post (JSON preferred over free-text), split 80/20:
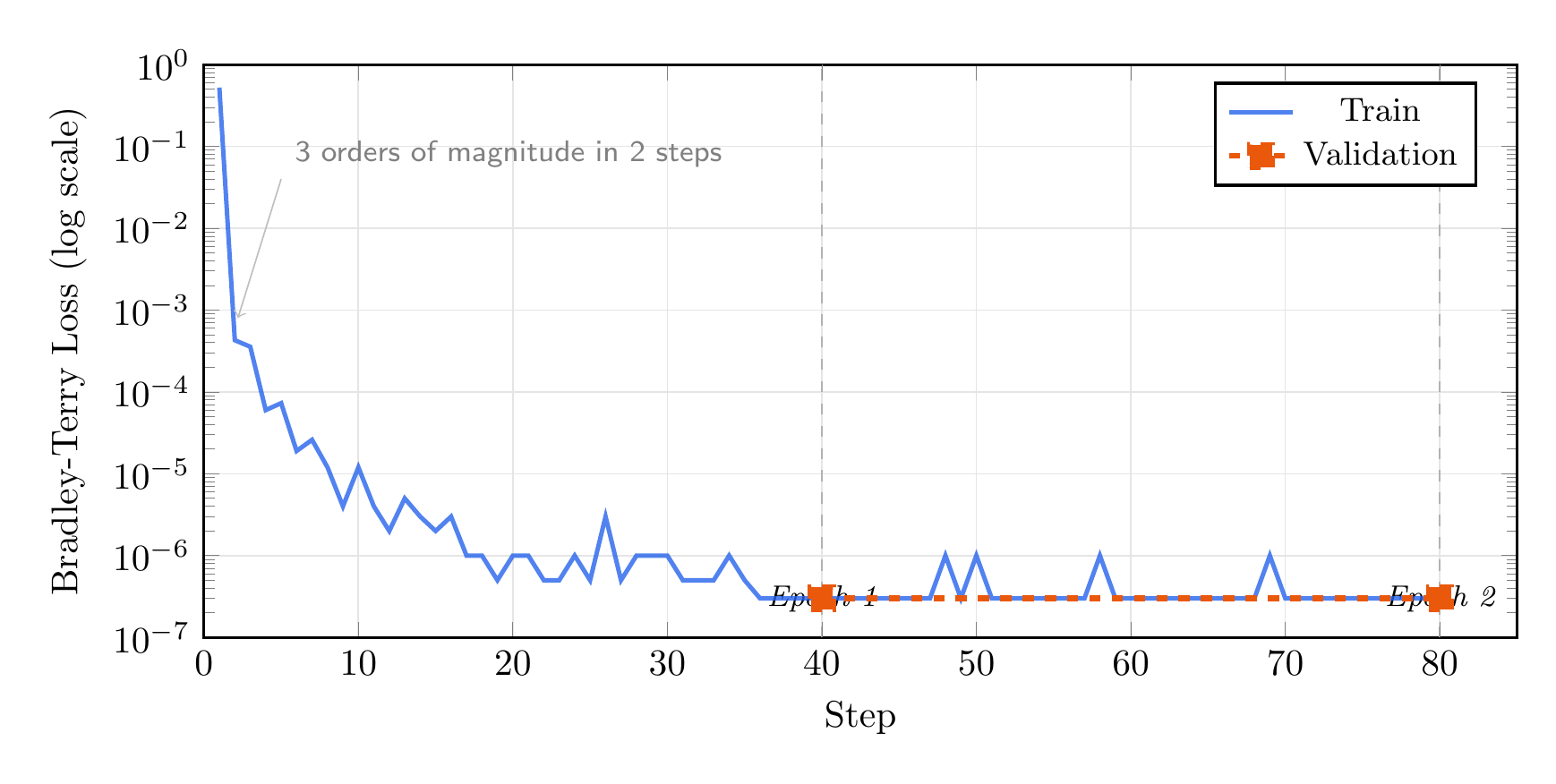
The loss drops from 0.52 to near-zero in about 5 steps, reaching 100% pairwise accuracy on both train and validation by the end of epoch 1. On a log scale you can see the loss continues to decrease through epoch 2, but the model has already learned the preference perfectly.
This makes sense: the distinction between JSON and free-text is unambiguous. A more nuanced preference task (e.g., “helpful vs. slightly less helpful”) would be much harder and would not converge this fast.
Comparing Explicit vs. Implicit Rewards
Here is the interesting part. DPO defines an implicit reward:
We can compute this from the DPO-trained model and compare it to the explicit reward model’s scores. I tested on three prompts, including Kafka which was not in the training data:
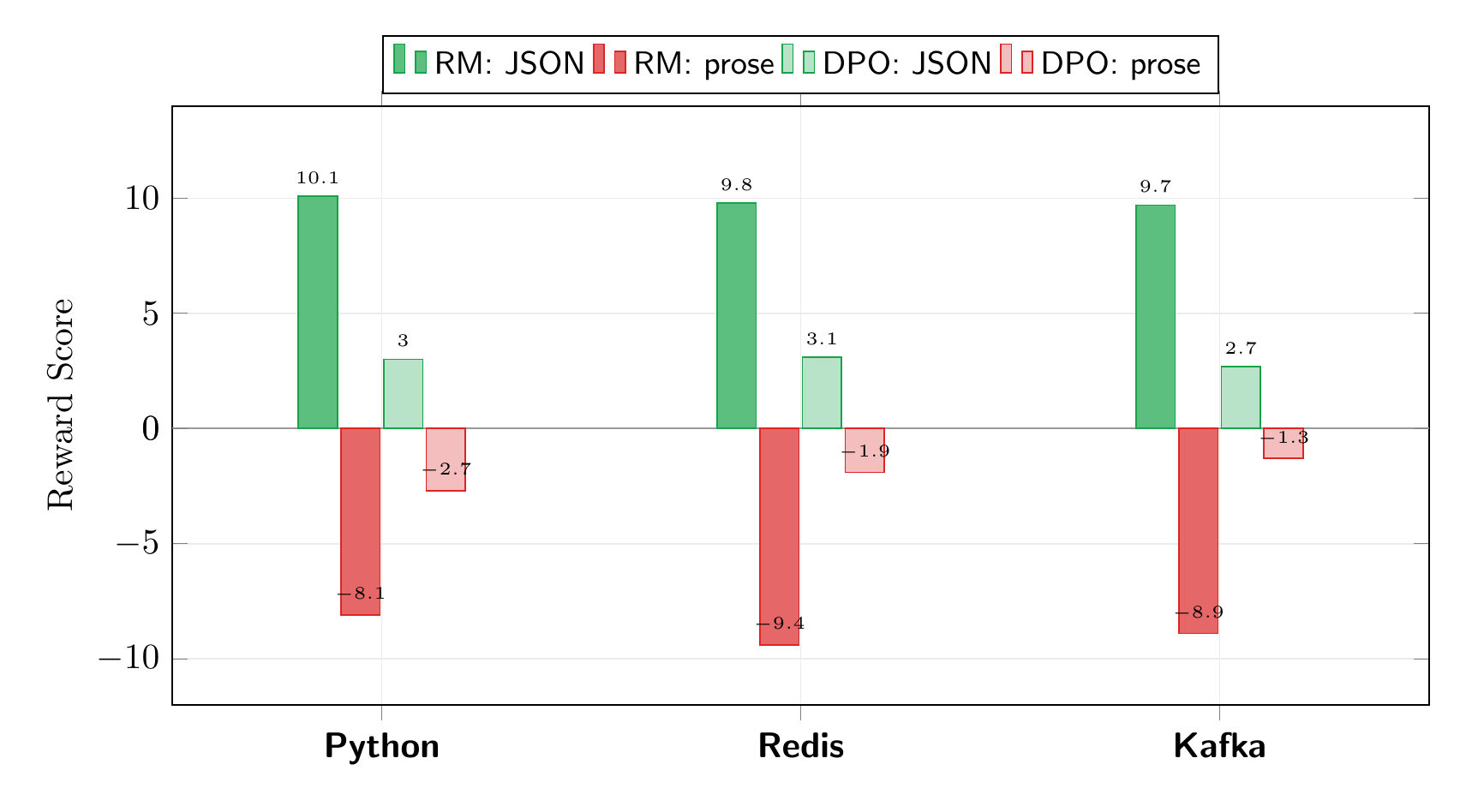
The absolute scales differ (the explicit reward model produces scores in the +/-10 range, while the implicit reward is in +/-3), but the ranking is identical: both consistently score JSON responses above free-text, even on unseen topics. This is exactly what the DPO paper predicts: DPO learns the same preference ordering as a reward model, just without training one explicitly.
A subtlety worth noting: computing the implicit reward correctly requires summing log-probability ratios over response tokens only, not the full sequence. If you average over the prompt tokens too, the signal gets diluted and the rankings can flip.
The Full RLHF Picture
Now we have all the pieces:
| Post | What | Role in RLHF |
|---|---|---|
| SFT | Supervised fine-tuning | Step 1: teach base behavior |
| This post | Reward model | Step 2: learn to score responses |
| (PPO) | Policy optimization | Step 3: optimize against reward |
| DPO | Direct preference optimization | Steps 2+3 combined |
DPO replaces the reward model + PPO with a single loss. But understanding the reward model helps you appreciate what DPO is doing under the hood.
When to Use an Explicit Reward Model
- Best-of-N sampling: generate N responses, score them all, return the highest
- Data filtering: score a large dataset and keep only high-reward examples for SFT
- Online RLHF with PPO: when you need a reward signal during generation
- Debugging: inspect what the model has learned to value
References
- Ouyang, L., et al. “Training language models to follow instructions with human feedback.” NeurIPS 2022. arXiv:2203.02155
- Rafailov, R., et al. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” NeurIPS 2023. arXiv:2305.18290
- Bradley, R. A. & Terry, M. E. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.” Biometrika, 1952.
- The full code for this post is available at github.com/mrrostam/blog-code/reward